
Why That New “Science-Backed” Supplement Probably Doesn’t Work
[ad_1]
I applied to have a stock comeback to folks who’d check with me to generate an report about the incredible stamina-maximizing homes of eye of newt or toe of frog or regardless of what. “Send me the final results of a peer-reviewed, randomized, double-blinded demo,” I’d say, “and I’d be pleased to compose about it.” But then they started out to connect with my bluff. In a great deal the exact way that every little thing in your fridge both of those results in and stops cancer, there’s a review out there somewhere proving that anything boosts stamina.
A new preprint (a journal posting that hasn’t still been peer-reviewed, ironically) from researchers at Queensland College of Know-how in Australia explores why this appears to be the circumstance, and what can be carried out about it. David Borg and his colleagues comb through countless numbers of content articles from 18 journals that aim on activity and workout medicine, and unearth telltale patterns about what receives published—and perhaps much more importantly, what doesn’t. To make sense of the reports you see and choose whether the hottest sizzling efficiency aid is well worth experimenting with, you also have to think about the scientific studies you really do not see.
Typically, the threshold for achievement in experiments has been a p-value of significantly less than .05. That usually means the outcomes of the experiment appear so promising that there’s only a one particular-in-20 chance that they’d have happened if your new miracle supplement experienced no result at all. That seems reasonably simple, but the true-globe interpretation of p-values rapidly gets both equally difficult and controversial. By one estimate, a research with a p-worth just below .05 truly has about a a single-in-3 opportunity of getting a fake optimistic. Even worse, it offers you the deceptive effect that a solitary analyze can give you a definitive indeed/no remedy.
As a final result, scientists have been hoping to wean them selves off of the “reign of the p-benefit.” One choice way of presenting results is to use a self-assurance interval. If I tell you, for illustration, that Hutcho’s Hot Tablets fall your mile time by an average of five seconds, that seems excellent. But a self esteem interval will give you a greater feeling of how trustworthy that consequence is: though the mathematical definition is nuanced, for simple purposes you can believe of a confidence interval as the vary of most very likely results. If the 95-percent self-assurance interval is involving two and eight seconds more quickly, which is promising. If it’s among 25 seconds slower and 30 seconds quicker, you’d presume there’s no actual outcome unless of course further more evidence emerges.
The risks of so-known as p-hacking are effectively-known and generally accidental. For example, when sports researchers were being offered with sample knowledge and requested what their up coming techniques would be, they were considerably additional probable to say they’d recruit extra participants if the present-day details was just outside the house of statistical significance (p = .06) than just inside it (p = .04). These sorts of choices, in which you stop gathering data as before long as your benefits show up to be substantial, skew the total physique of literature in predictable methods: you stop up with a suspicious selection of experiments with p just beneath .05.
Employing self-confidence intervals is intended to assistance relieve this problem by switching from the indeed/no attitude of p-values to a far more probabilistic standpoint. But does it definitely modify everything? Which is the question Borg and his colleagues set out to respond to. They utilized a text-mining algorithm to pull out 1,599 examine abstracts that employed a sure sort of assurance interval to report their success.
They targeted on experiments whose final results are expressed as ratios. For illustration, if you’re testing regardless of whether Hutcho Pills minimize your risk of strain fractures, an odds ratio of 1 would reveal that runners who took the drugs ended up equally most likely to get hurt compared to runners who did not just take the products. An odds ratio of 2 would suggest that they have been twice as likely to get injured a ratio of .5 would reveal that they have been half as most likely to get hurt. So you may possibly see success like “an odds ratio of 1.3 with a 95-p.c assurance interval between .9 to 1.7.” That self-confidence interval presents you a probabilistic perception of how very likely it is that the drugs have a authentic effect.
But if you want a far more black-and-white remedy, you can also question whether the self confidence interval includes 1 (which it does in the prior instance). If the self-confidence interval incorporates 1, which corresponds to “no impact,” which is loosely equal to saying that the p-price is previously mentioned .05. So you could possibly suspect that the exact values that guide to p-hacking would also direct to a suspicious number of confidence intervals that just hardly exclude 1. That is exactly what Borg went seeking for: upper confidence interval limits among .9 and 1, and lessen limits amongst 1 and 1.2.
Guaranteed enough, which is what they identified. In impartial facts, they calculate that you’d count on about 15 percent of reduce limitations to lie involving 1 and 1.2 instead they discovered 25 per cent. Similarly, they discovered four occasions as lots of upper restrictions amongst .9 and 1 as you’d anticipate.
Just one way to illustrate these final results is to plot something identified as the z-worth, which is a statistical evaluate of the strength of an result. In concept, if you plot the z-values of thousands of research, you’d be expecting to see a ideal bell curve. Most of the final results would be clustered all-around zero, and progressively less would have both really strongly optimistic or very strongly adverse results. Any z-benefit much less than -1.96 or greater than +1.96 corresponds to a statistically sizeable result with p significantly less than .05. A z-price amongst -1.96 and +1.96 signifies a null consequence with no statistically major finding.
In practice, the bell curve will not be fantastic, but you’d nonetheless expect a quite sleek curve. In its place, this is what you see if you plot the z-values from the 1,599 studies analyzed by Borg:
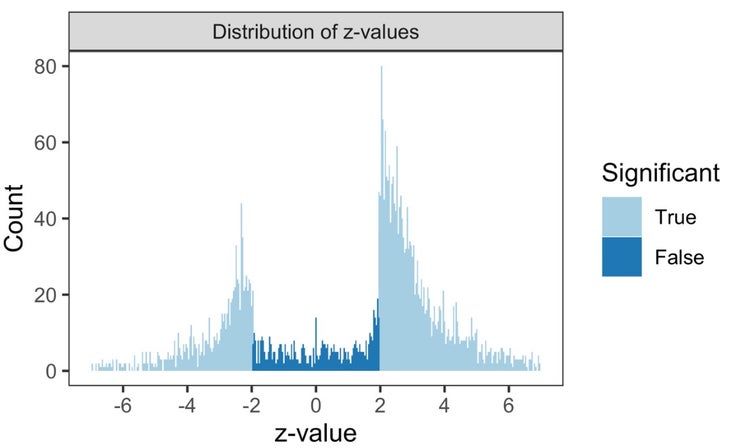
There’s a giant lacking piece in the center of the bell curve, wherever all the scientific studies with non-important success should really be. There are likely plenty of distinctive explanations for this, the two driven by decisions that scientists make and—just as importantly—decisions that journals make about what to publish and what to reject. It’s not an straightforward difficulty to address, simply because no journal desires to publish (and no reader needs to study) hundreds of scientific tests that conclude, over and about, “We’re not however sure whether this operates.”
One particular tactic that Borg and his co-authors advocate is the wider adoption of registered reviews, in which experts post their study plan to a journal prior to functioning the experiment. The approach, including how success will be analyzed, is peer-reviewed, and the journal then claims to publish the effects as lengthy as the scientists adhere to their stated program. In psychology, they observe, registered experiences generate statistically major outcomes 44 % of the time, compared to 96 percent for normal research.
This appears to be like a very good prepare, but it’s not an fast deal with: the journal Science and Medicine in Soccer, for instance, released registered experiences three many years ago but has still to acquire a solitary submission. In the meantime, it’s up to us—journalists, coaches, athletes, intrigued readers—to utilize our personal filters a little a lot more diligently when presented with thrilling new studies that assure quick gains. It’s a challenge I have wrestled with and frequently come up shorter on. But I’m retaining this rule of thumb in thoughts from now on: a single research, on its individual, means nothing.
For more Sweat Science, sign up for me on Twitter and Fb, signal up for the electronic mail e-newsletter, and verify out my e book Endure: Intellect, Physique, and the Curiously Elastic Limits of Human General performance.
[ad_2]
Resource backlink






